
|
|
DecisionTreesDecision Tree ClassifiersDecision trees are a well-known classifier type for both discrete and continuous-valued features. One advantage of decision trees is that they produce very interpretable decision rules; they are easy to evaluate "by hand", so that the factors that went into the class decision can be easily stated. A decision tree classifier consists of a sequence of "comparison nodes", at which a single feature of the data point is examined. For a continuous-valued feature, the decision node compares the feature value to a threshold, and depending on whether the value is above or below the threshold, recurses down the decision tree to the left or right. At some point, this process reaches a "decision node", at which one of the possible class categories is output. For discrete-valued features, it does not really make sense to "threshold" a value. Instead, there are a number of possible options. The most straightforward is to have one child node per possible feature value. However, this results in a non-binary tree, possibly with a high branching factor, and can complicate the score function used in learning (see discussion in Duda and Hart). Another possibility is to keep the binary tree shape, in which case some discrete values are assigned to the "left" and all others to the "right" child.
Learning Decision TreesEach comparison node of a decision tree consists of the selected feature index, and a threshold for comparison. Typically, we determine the values of these parameters by a simple exhaustive search, looping over all possible features and all possible thresholds and evaluating some score function, then picking the parameters that result in the best score. Note that, although the threshold is a continuous value, there are only a finite number of possible decisions to make on a given training set. In particular, when the training data are sorted along the feature being considered, any threshold falling between two given data points results in exactly the same rule on the training data, and thus are typically indistinguishable. We can thus enumerate the number of unique thresholds, and typically pick the mean of the two nearest data points as the value. Score functionsThe purpose of a score function is to decide how good any particular split is. You might think that the classification accuracy would make a good score function, since minimizing it is our true goal. However, as usual, classification accuracy is not particularly well behaved. It will often focus on selecting "very specialized" rules that try to get one more data point correct, rather than trying to split groups of data in a more holistic way. Also, among rules that do not get any additional data points correct, it provides no guidance whatsoever. One useful score function is based on the entropy of the class values within each subtree. The empirical entropy, measured in bits, for a data set How does entropy help us decide on a partitioning? We can use entropy to calculate the so-called expected information gain, which is the average reduction in entropy we see when we adopt some data split. In particular, suppose that we split a data set A common alternative to entropy is the so-called Gini index, which measures the variance of the class variable, rather than its entropy. The Gini index equivalents of the above equations are:
Complexity Control and PruningThe complexity of a decision tree is essentially determined by its depth. (How many parameters can a binary decision tree of depth d have?) We may therefore want to control this complexity by reducing the depth. Common stopping rules include not proceeding past some maximum depth d, or not continuing to split nodes of the tree that have fewer than K training data points associated with them (since we may not trust our ability to learn a general rule based on so few data). Reducing complexity may be particularly desirable if we feel that the extra depth did not significantly improve our performance. It is often hard to tell whether a split will significantly improve performance when the tree is initially being constructed. For example, it is easy to make examples where one split provides no measurable gain in accuracy or score, but allows the next level's split to have significant gains. For this reason, one usually constructs the entire tree and then prunes. Given the full decision tree, we start at the leaves and walk upward, checking whether each parent had an accuracy nearly equal to that given by its children. If the gain is below some threshold, we prune the children and continue upward; if not, we cease recursing for this node or its ancestors. Decision StumpsA decision stump is a single-layer decision tree, i.e., a threshold value applied to a single feature. Although an extremely weak learner (it can only represent extremely simple decision boundaries), it is commonly used in techniques that leverage many weak learners to create a single more powerful learner, such as ensemble methods. Related links and more information
|
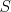 is given by
is given by
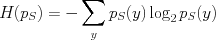 where
where 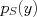 is the empirical distribution of the class value
is the empirical distribution of the class value  , i.e., the fraction of data in set
, i.e., the fraction of data in set 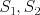 with
with 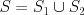 . We compute the expected information gain as
. We compute the expected information gain as
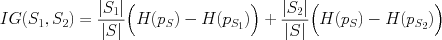
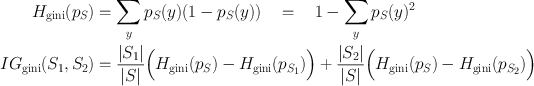 Again, H is at its minimum (zero) when the variable y is deterministic (a single class) within the subset S, and IG measures the gain, or increase in determinism, caused by conditioning on the split into subsets S1, S2.
Again, H is at its minimum (zero) when the variable y is deterministic (a single class) within the subset S, and IG measures the gain, or increase in determinism, caused by conditioning on the split into subsets S1, S2.