
|
|
KMeansThe k-means algorithm is a simple and well-known technique for finding k clusters in a set of data. Suppose that we have N data points Notationally, suppose that we identify each data point This defines a two-part problem -- if we knew the cluster centers Formally, we can think of K-means as minimizing the following cost function:
K-means updates in two steps:
Consider minimizing over Now consider minimizing over some cluster center This process is then repeated until convergence. To see that it converges, note that each step is decreasing the cost function (no update will ever increase the cost function) and that the cost function is bounded below (it is greater than zero). In practice, at some point the nearest cluster center to each data point will be the one already assigned to it, meaning that the z variables do not change; then, the cluster centers will not change either, since they are already equal to the mean of those data. Then, obviously, the z's will not change at the next iteration either, and the system is converged.
InitializationK-means greedily optimizes the cost function C(.), but is easily stuck in local minima. This makes initialization important; often K-means will be run many times from different initializations, and the best run selected. A few common means of initializing the cluster centers include:
Often it is helpful to inject a bit of randomness into procedures like "Farthest", in part so that they can be re-run several times and the best selected. For example, having found the distance Example code% INPUTS % Data X : n-by-d % # of clusters K pi = randperm(n); % initialize cluster centers, in this case C = X(pi(1:K),:); % to a random set of K data points z = zeros(n,1); % allocate memory for cluster assignments while (~converged) for i=1:n, dists = sum( (C - repmat(X(i,:),[K,1])).^2 , 2); % compute distances from each cluster center [tmp,z(i)] = min(dists); % and assign datum i to the nearest cluster end for j=1:K, % now update each cluster center j C(j,:) = mean(X(z==j,:),1); % to be the mean of the assigned data end converged = ... % compute convergence condition based on change in C, or change in sum of squared error end; |
 , each made up of d features.
In k-means, we describe each cluster c by a "center"
, each made up of d features.
In k-means, we describe each cluster c by a "center" 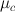 in the d-dimensional feature space, and define the similarity of a data point x to center
in the d-dimensional feature space, and define the similarity of a data point x to center  . Obviously, we do not know this association; the "true" values of z are hidden from us.
. Obviously, we do not know this association; the "true" values of z are hidden from us.
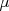 , it would be relatively easy to figure out which data points went with each cluster; alternatively, if we knew the association variables, it would be straightforward to determine cluster centers that most accurately described them. K-means will alternate between these two steps, assuming
, it would be relatively easy to figure out which data points went with each cluster; alternatively, if we knew the association variables, it would be straightforward to determine cluster centers that most accurately described them. K-means will alternate between these two steps, assuming  the total Euclidean distance of each data point from its assigned cluster center.
the total Euclidean distance of each data point from its assigned cluster center.

 . The only term in C(.) that depends on
. The only term in C(.) that depends on  . Clearly, this will be minimized by selecting the closest cluster center
. Clearly, this will be minimized by selecting the closest cluster center 
 , i.e., the distances of the data points that are currently assigned to cluster c. It is straightforward to show that the minimum sum of squared distances is achieved by setting
, i.e., the distances of the data points that are currently assigned to cluster c. It is straightforward to show that the minimum sum of squared distances is achieved by setting 

 of each point
of each point 