
|
|
BoostingBoosting is another, very popular style of ensemble classifier. Boosted ensembles of learners are trained in a sequential way, with each new learner focusing on the data that are not yet well classified. The basic outline of a boosted learner is as follows. Take any type of base classifier, but make sure that it can train on weighted data. In other words, rather than attempting to minimize the classification error with our base learner, we will need to minimize a weighted classification error,
Now, beginning with uniform weights Finally, we combine the learners by evaluating them, but rather than a simple average we take a weighted average, multiplying each learner j's decision by a linear coefficient The precise details of this process are typically what distinguishes different boosting algorithms. AdaBoostA very popular algorithm is AdaBoost, which was also the boosting algorithm that first popularized the framework. It is easiest to describe AdaBoost using classes In AdaBoost, we compute the coefficient for each learner j based on its weighted error rate,
The final classifier is given by summing the weighted individual learners and applying a threshold:
Boosting and Surrogate Cost FunctionsBoosting algorithms can be shown to correspond to a particular surrogate loss function (replacement for the classification error rate). In particular, AdaBoost corresponds to the exponential loss function
|
 Note that if
Note that if  for all i, this is exactly the standard empirical classification error.
for all i, this is exactly the standard empirical classification error.
 . Predict
. Predict  for each training example. For any training examples we get right, reduce the weight; for training examples we get wrong, increase it. Then train the next learner and repeat. This focuses our next learner on those data that we have consistently gotten wrong most often: the "hard" data points.
for each training example. For any training examples we get right, reduce the weight; for training examples we get wrong, increase it. Then train the next learner and repeat. This focuses our next learner on those data that we have consistently gotten wrong most often: the "hard" data points.
 .
.
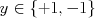 .
.
 We then use this quantity to update the weights as well:
We then use this quantity to update the weights as well:
 and re-normalize the weights to sum to one. Note that, since
and re-normalize the weights to sum to one. Note that, since 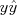 is either +1 or -1 -- it equals +1 if the prediction agrees with the true class, and -1 if it does not. This up-weights incorrect predictions, and down-weights correct ones.
is either +1 or -1 -- it equals +1 if the prediction agrees with the true class, and -1 if it does not. This up-weights incorrect predictions, and down-weights correct ones.

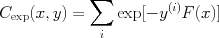 Note again that, if y and F(x) share the same sign (the prediction is correct), this value will be small (and smaller the more confident F(x) is). At the decision boundary, the cost is 1, and continues to increase the more F(x) is confident in its incorrect prediction. The exponential loss function is nice in part because it is both convex and upper bounds the 0/1 loss (classification error). The first property makes it easy to optimize, while the second means that as we optimize we are at least trying to push downward on the classification loss below us.
Note again that, if y and F(x) share the same sign (the prediction is correct), this value will be small (and smaller the more confident F(x) is). At the decision boundary, the cost is 1, and continues to increase the more F(x) is confident in its incorrect prediction. The exponential loss function is nice in part because it is both convex and upper bounds the 0/1 loss (classification error). The first property makes it easy to optimize, while the second means that as we optimize we are at least trying to push downward on the classification loss below us.