
|
|
ClassificationClassifiersWhen the signal we wish to predict is discrete-valued, we call the problem of supervised learning classification. A classifier is, at heart, a recipe for making a decision, since it must select (predict) one of the discrete outcomes. Classification boundariesOne natural way to describe a classifier is through its boundary, the set of points at which it transitions from making one decision to another. (For a binary classifier, this almost completely describes the classifier.) By understanding what types of classification boundaries can be obtained by a type of learner, we can understand when it is likely to work well, and when poorly. Classification accuracyThe most common way of measuring the performance of a classifier is to simply measure the accuracy of the classifier (fraction of the time we expect it to output the correct answer), or conversely, the error rate (fraction of the time we expect it to be incorrect). We can measure the empirical error rate by simply counting the fraction of data points on which our prediction is wrong:
SeparabilityA data set is said to be separable by a particular learner if there is some instance of that learner (i.e., a setting of the parameters) that will perfectly predict the training data. In this case, the learned function is able to exactly reproduce the target values on those data points, "separating" the classes. |
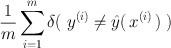 where the Kroneker
where the Kroneker 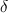 function is 1 if the condition is satisfied, and zero otherwise.
We can compute the empirical error rate on the training data (training error) or on validation or test data (test error).
function is 1 if the condition is satisfied, and zero otherwise.
We can compute the empirical error rate on the training data (training error) or on validation or test data (test error).