
|
|
GmmEMGaussian mixture models are perhaps the most common model used for explaining (or modeling) data using clustering ideas. Although standard Gaussian models are common in many situations, they are not appropriate for many problems. For example, it is common to suppose that grades in a course should be Gaussian distributed (given enough students, of course). However, suppose that our data consist of grades for two courses, lumped together. If the courses have very different level of difficulty, the resulting distribution of grades will certainly not look Gaussian -- for example, the histogram might show two modes, centered at the averages within each course. How might we model such data, that consist of a mixture of two (or more) different populations? Mixture models address this task. Instead of using a single Gaussian distribution, we can define a weighted sum of Gaussian components (for example, one per course). In this case, we have a set of Gaussian parameters (mean The log-likelihood of the data under this model is given by
GMM as ClusteringAs in the above example, we typically do not know which data come from each component. In fact, if we knew which data were which, we could more easily model the groups individually. Alternatively, if we knew the component models, we might be able to determine which component each datum came from. Thus identifying both the assignment of data to each component, and the "description" of the component ( As in K-means, let us associate a variable Expect cll , Optim and variat interp Lower bound with q |
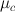 and covariance
and covariance  ) for each component, and a "mixture weight" $\pi_c$ that describes the relative proportion of data from group c in the full data. Then, the overall distribution is a weighted average of these components:
) for each component, and a "mixture weight" $\pi_c$ that describes the relative proportion of data from group c in the full data. Then, the overall distribution is a weighted average of these components:
 where
where  is the standard Gaussian distribution,
is the standard Gaussian distribution,
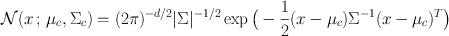
 As is typical in probabilistic models, we would like to optimize the log-likelihood over the model parameters
As is typical in probabilistic models, we would like to optimize the log-likelihood over the model parameters  , so that the data are explained as well as possible by the model. However, this optimization cannot be solved in closed form, in part due to the "log sum exp" form taken on by the log of a mixture of Gaussians. One possibility, of course, is to optimize it directly via gradient ascent. However, an augmented form will give us other possibilities, and make the connection to other clustering algorithms more clear.
, so that the data are explained as well as possible by the model. However, this optimization cannot be solved in closed form, in part due to the "log sum exp" form taken on by the log of a mixture of Gaussians. One possibility, of course, is to optimize it directly via gradient ascent. However, an augmented form will give us other possibilities, and make the connection to other clustering algorithms more clear.
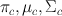 ) can be seen to be a variant of the classic formulation of clustering.
) can be seen to be a variant of the classic formulation of clustering.
 with each data point
with each data point  to indicate which component gave rise to this particular observation. If we were told this association, the data within each component would simply be Gaussian, and the association variables z would tell us 'which Gaussian component to evaluate. We can use this to write down the so-called "complete" log-likelihood of the data:
to indicate which component gave rise to this particular observation. If we were told this association, the data within each component would simply be Gaussian, and the association variables z would tell us 'which Gaussian component to evaluate. We can use this to write down the so-called "complete" log-likelihood of the data:
