
|
|
LinearClassifyLinear classifiersA linear classifier is one whose decision function is a linear function of the input features, e.g., for a binary classifier between classes Linear classifiers are sometimes called "perceptrons", their historical name when proposed by Rosenblatt and studied in the early days of artificial intelligence; they are a very simple type of neural network. The decision boundary for a linear classifier is also linear. The decision boundary are the points at which we transition from decision +1 to decision -1; in our example, this occurs at precisely the solution to the linear equation Linearly separable dataIt is useful to differentiate between data sets that can be linearly separated, i.e., there exists a linear classifier that achieves zero training error, and those that cannot. A few examples are shown here, for both real-valued features and binary-valued features:
As can be seen, a perceptron / linear classifier cannot correctly learn an exclusive or (XOR) function, a result famously discussed by Minsky and Papert in 1969. Training linear classifiersWhat makes a good classifier? The usual measure of error for classification is the classification error, or misclassification rate -- the number of mistakes (misclassifications) made on the data. Typically, we would like to minimize the misclassification rate over the training data, by finding a set of parameters (weights) that make few errors. As with linear regression, we can notionally think about exploring the space of parameters, assigning each point a cost, and searching for the point with minimum cost. However, the misclassification rate is often difficult to optimize directly. First, it is not smooth -- it changes value only when the decision boundary passes a data point, so it is constant until it changes abruptly one way or the other. There is thus very little "signal" about which direction we should modify the parameters, in order to reduce the error. Another consequence of such "flat" values can be seen when the data are linearly separable -- there may be a large set of linear classifiers that achieve zero error, but intuitively we can guess that some are likely to be better than others. Classification accuracy alone, however, judges these classifiers exactly the same way.
Such difficulties motivate the use of "surrogate" loss functions -- error functions that we can use to replace the classification error that will be easier for us to optimize. The typical training approach is to learn parameters to optimize the surrogate loss, and hope (sometimes with good reason) that this also produces good classification accuracy. Linear classification as a regression problemThe linear classifier has the form of thresholding a linear function of the features. How can we learn a good linear function? One simple way we could consider is just to learn a linear predictor of the class in the regression sense, and then threshold that value. So, for example, we define a variable This is an example of a surrogate loss. We are normally interested in our misclassification rate, i.e., the fraction of data on which In some cases it will, and in some it will not. |
||||||||||||
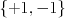 , a decision of the form
, a decision of the form
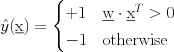 where
where  is our usual vector of feature values, and
is our usual vector of feature values, and 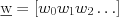 is a vector of weights.
Note here that we have used classes
is a vector of weights.
Note here that we have used classes 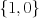 binary classes, to highlight that our decision rule is choosing the "sign" of the linear response
binary classes, to highlight that our decision rule is choosing the "sign" of the linear response  .
.
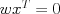 . For example, for two features
. For example, for two features 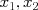 we can solve to find the decision boundary, which is a line in the two-dimensional feature space:
we can solve to find the decision boundary, which is a line in the two-dimensional feature space:
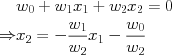
 , equal to the class value c, to predict using regression. We then regress the data
, equal to the class value c, to predict using regression. We then regress the data  to find parameters
to find parameters 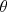 , and finally, we define our (real-valued) regression prediction as
, and finally, we define our (real-valued) regression prediction as  and our discrete class prediction as
and our discrete class prediction as 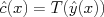 .
.
 , or:
, or:
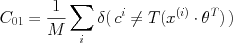 But, our training of the model parameters
But, our training of the model parameters  So the model we find will have a good
So the model we find will have a good 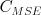 , but will it also have a good
, but will it also have a good 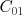 ?
?