
|
|
Projects /
DataMiningData MiningData mining describes the task of organizing and searching massive quantities of data for patterns of interest, for example summarizing large subsets of the data (clustering), finding unusual or unexpected patterns (anomaly detection), or constructing new, more meaningful representations of the data (latent space representations). Our group uses probabilistic models to perform these tasks -- graphical models are learned from the data to represent and assess expected behavior.
Mining sensors and count data We have used graphical models to provide automatic event (anomaly) detection in data consisting of discrete counts, using variants of Poisson processes to model the underlying phenomena. Data examined include (a) counts of entries and exits through one or more doors of a UCI campus building, captured via a wireless optical sensor (image, right; data available from the UCI ML repository); (b) vehicle counts collected via loop sensor data on the I-405 freeway, collected by CalTrans (data available from CalTrans' website); (c) traffic accident data (date and time of accident report) from North Carolina. 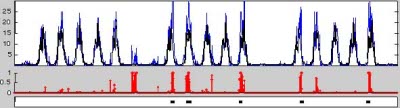 We used Markov-modulated Poisson processes to describe the superposition of normal and abnormal behavior in the data. "Normal" behavior are represented using a standard, time-varying Poisson process, while "event" behavior consists of sustained periods with increases (or more rarely, decreases) in the number of counts observed. A Markov chain model captures the notion of event persistence, allowing the model to find slight but sustained changes in activity and more accurately estimate the duration of a detected event. An example is shown at right, where the blue curve shows the observed counts, black the estimated normal profile; red bars show the estimated probability of an event at each time, and the bottom-most panel shows a partial ground truth of known events, held out from the model for validation purposes. Matlab code available here.
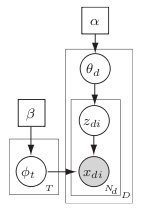 Text mining and LDAWe have also worked with the latent Dirichlet allocation (LDA) model for mining unstructured collections of text, such as books, articles, or web pages. LDA describes each document as a collection of semantic "topics", only a few of which appear in any given document. The topics in each document, and words associated with each topic, are learned in an unsupervised manner. Our work has focused on making the estimation process more computationally efficient, developing fast sampling algorithms (Porteous et al. 2008) and improving the efficiency and accuracy of parallel or distributed implementations (Ihler & Newman 2009), which allow ever-larger data sets to be automatically organized.
Computational BiologyHigh-throughput experiments in biology have made it critical to identify genes which are expressed in interesting ways, for example cycling through periodic patterns over time. Typically, many thousands of genes are evaluated and must be identified and organized by their expression profiles. We have used graphical models to detect periodic behavior in genes (Chudova et al. 2009), and to improve our estimates of their shapes by separating out effects due to changes in the individual's rate of development (Liu et al. 2010). Another major problem in computational biology is identifying regulatory network structure, i.e., determining which genes or transcription factors play a role in controlling the subsequent expression of other genes. This problem can be formulated as learning a graphical model, where the connectivity of the graph is used to represent which pairs of genes are directly interacting. |